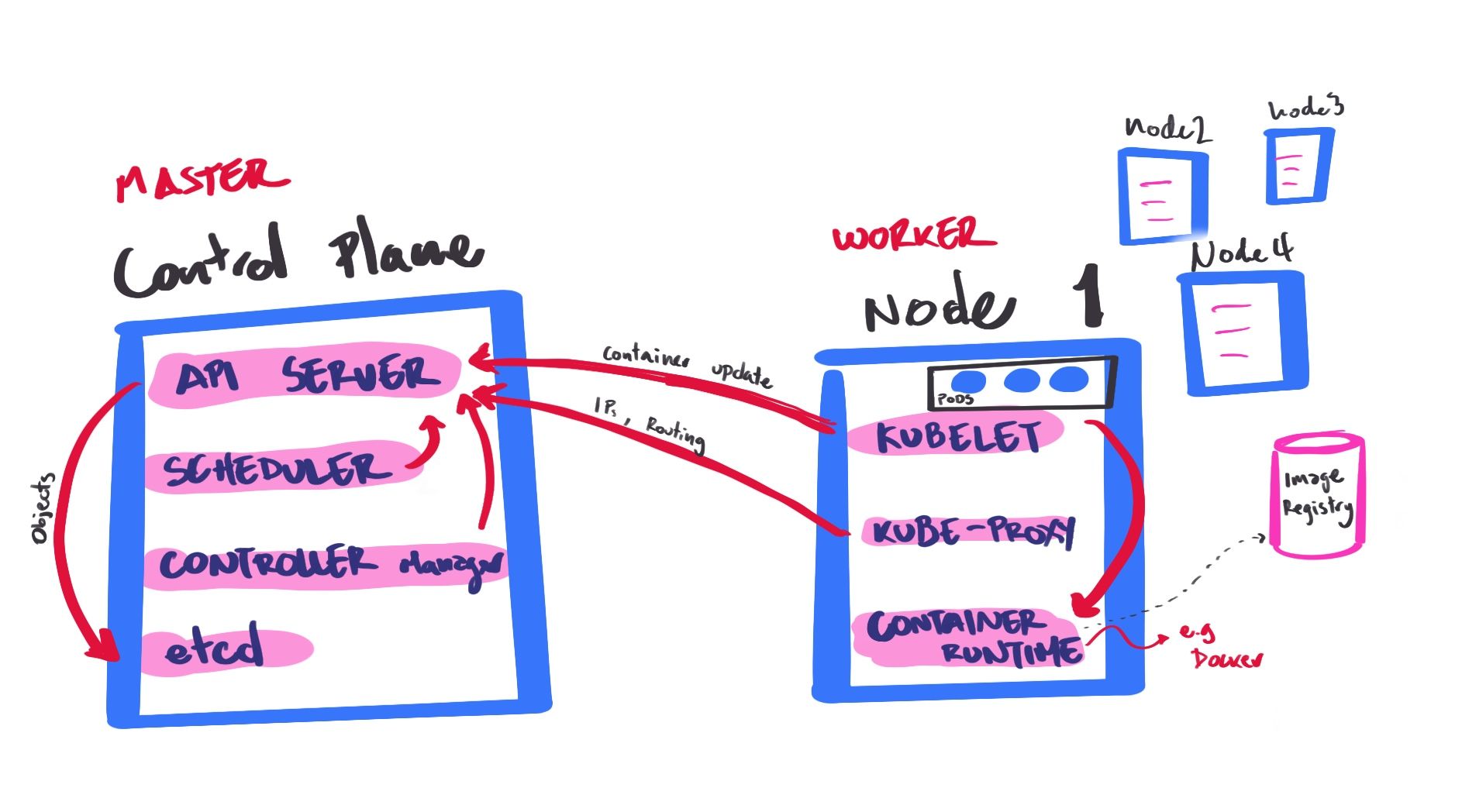
Master (1... *)
Worker (0... *)
Single node or 5000 node cluster is the same deployment, relocate app components to another node, focus on deploy and scaling, transparent for users
Pods, Services, etc are persistent entities, represent state of cluster = record of intent
k8s works to maintain that state → express record of intent with yaml files → kubectl
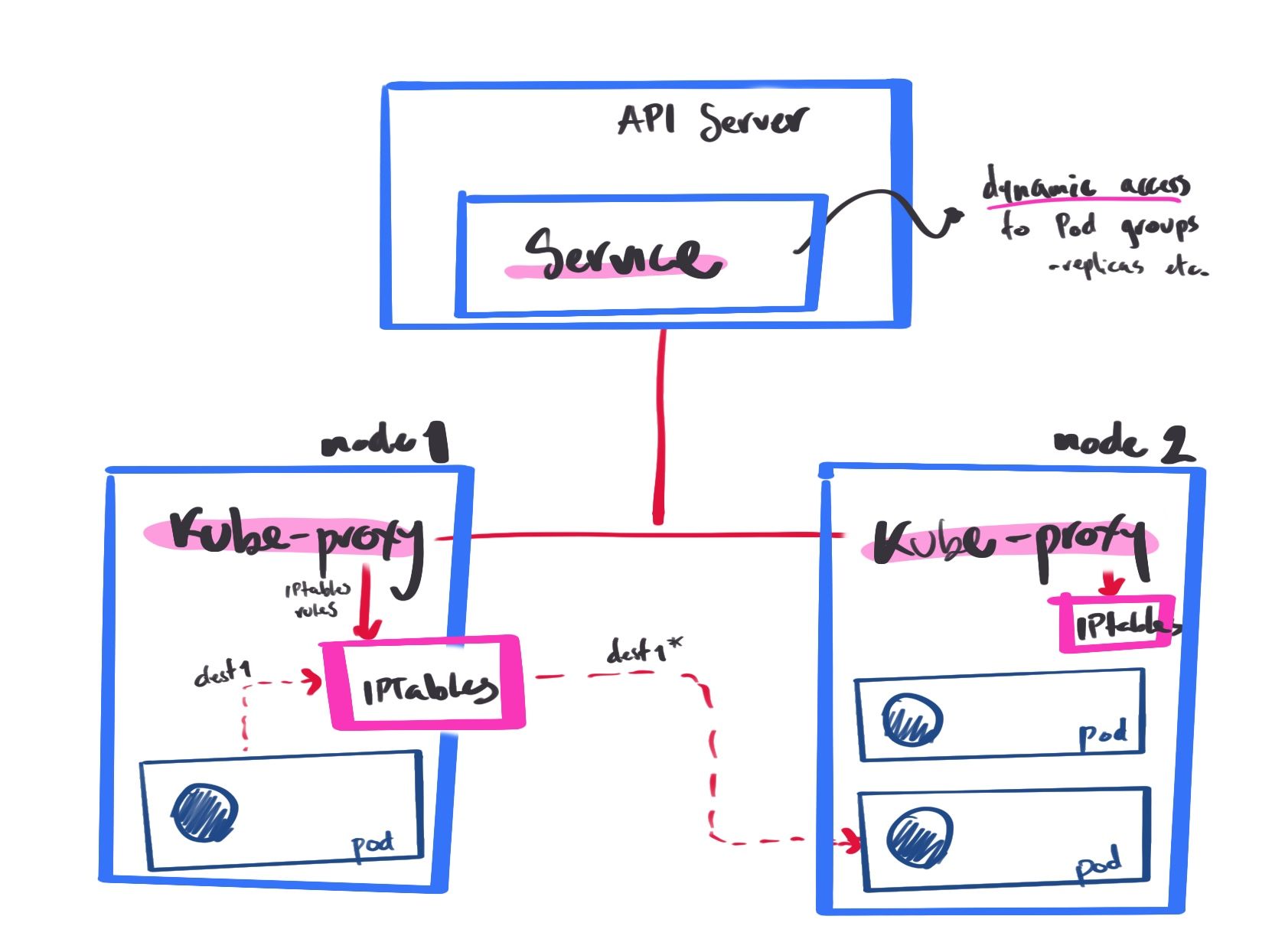
Service: Allows dynamic access to a group of replicas, pod stucture is unimportant (deleted and created with new IP)
handles traffic associated with a service by creating iptables rules — load balances traffic
API Server etcd Scheduler Controller Manager master 1 API Server etcd Scheduler Controller Manager master 2 API Server etcd Scheduler Controller Manager master 3 Load balancer kubelet worker 1 kubelet worker 2 kubelet worker 3 kubelet worker 4 standby Replicas of app and copies in multiple nodes + duplicate K8s components
kubectl get pods -o custom-columns=POD:metadata.name,NODE:spec.nodeName --sort-by spec.nodeName -n kube-system
custom query to check config and state of pod/nodes
In a HA setup you wil have multiple master nodes, to prevent scheduler and control manager racing and possibly duplicating objects, only one pair ( one master) is active at any time.
Use LeaderElect option to select the active component, informs others of which server is the leader. Achieved by creating an endpoint.
Chek via scheduler yaml kubectl get endpoints kube-scheduler -n kube-system -o yaml — periodically updates the resource, every 2 secs (default)
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity": "f2c3d18a641c.mylabserver.com_
Replicating etcd Stacked (each node has its own etcd) or external (to the cluster) topologies
external to the k8s cluster, consensus algo to progress state. State change requires majority (odd num) — 3 to 7 etcd instances usually
# 1. get binaries
# 2. put in place
/usr/local/bin
# 3. create dir
/etc/etcd and /var/lib/etcd
# 4. create the systemd unit file for etcd
# 5. enable and start etcd service
sudo kubeadm -init —config=kubeadm-config.yaml initialize cluster w/ stacked etcd
kubectl get pod -n kube-system -w watch pods
Securing cluster communications
pod Role Role binding Admins Namespace X Service Account pod Namespace Y Service Account X
Set all comms to https
API Server → CRUD interface to modify the cluster state over a RESTful API
Authentication: determined by http header or certificate, back to API server Authorization: determine if the action is available to the authenticated user. e.g., can create resource? Admission: Plugins modify the resource for reasons, such as applying defaults Resource validation: validates before puting into etcd Change etcd: make changes and return the response Bypass (by default) using self signed cert at .kube/config
User has Roles (allows actions on Resources)
Role: what can be done Role binding: Who can do it Example:
Admin Group ↔Role binding ↔ Role ↔✅ Pod
ServiceAccount → Pod authenticates to the API server, identity of the app running in the Pod
Must bbe in the same namespace as the Pod
Running end-to-end tests kubetest commontool for testing
A preventive checklist
Deployments can run Pods can run kubeclt run nginx --image=nginx && kubectl get deployments && kubectl get pods Pods can be accessed directlykubectl port-forward nginx-6dasaghug 8081:80 && curl 127.0.0.1:8081 Logs can be collectedkubectl get pods && kubectl logs nginx-6db489d4b7-fl869 Commands run from pod kubectl exec -it nginx-6db489d4b7-fl869 -- nginx -vnginx version: nginx/1.19.2 Services can provide access kubectl expose deployment nginx --port 80 --type NodePort curl -I localhost:31297 Nodes are healthy kubectl describe nodes Pods are healthykubectl describe pods Installing and testing components Install 3 node cluster
Expose port on the podkubectl create deployment nginx --image=nginxkubectl get deployments -o widekubectl get podskubectl port-forward nginx-86c57db685-qwv5s 8081:80
Verify nginx versionkubectl exec -it nginx-86c57db685-qwv5s -- nginx -v
Create a servicekubectl expose deployment nginx --port 80 --type NodePortkubectl get svckubectl get pods -o wide curl -I ip-10-0-1-102:30142
Documentation: Creating a cluster with kubeadm
Managing the cluster Upgrading kubectl get nokubectl version --shortkubeadm version
unmarking kubectl and kubeadm
upgrading
sudo kubeadm upgrade apply v1.18.5sudo apt-mark unhold kubectl
update kubeadm
apt-mark unhold kubeadm kubelet
apt install -y kubeadm=1.18.5-00
kubeadm upgrade plan
kubeadm upgrade apply v1.18.9
kubectl get noapt-mark unhold kubectl && apt-mark hold kubectl
each node
apt-mark unhold kubelet
sudo apt install -y kubelet=1.18.5-00
apt-mark hold kubeletUpgrading OS Move pods from that node. Kubelet might attempt to restart pod in same node, if longer downtime, controller will reschedule some other pod
kubectl drain <node-identifier>
kubectl get pods -o wide
kubectl drain ed092a70c01c.mylabserver.com --ignore-daemonsets
$ node/ed092a70c01c.mylabserver.com evicted
kubectl get no
# do maintenance here on disabled server (no pods will run here)
reenable witth kubectl uncordon <node-identifier>
Remove completely from cluster
kubectl drain ed092a70c01c.mylabserver.com --ignore-daemonsets
kubectl delete node ed092a70c01c.mylabserver.comAdd a new node
kueadm token generate
kubeadm token create xxxxx --ttl 2h --print-join-command
In new worker node, run the join command from previous step Backing up and restoring etcd is the only requirement, thus backup
# get etcd client binaries, unzip, and move
wget <https://github.com/etcd-io/etcd/releases/download/v3.3.25/etcd-v3.3.25-linux-amd64.tar.gz>
tar xvf etcd-v3.3.25-linux-amd64.tar.gz
mv etcd-v3.3.25-linux-amd64/* /usr/local/bin
# run backup command using certificates
ETCDCTL_API=3 etcdctl snapshot save snapshot.db --cacert /etc/kubernetes/pki/etcd/server.crt --cert /etc/kubernetes/pki/etcd/ca.crt --key /etc/kubernetes/pki/etcd/ca.key
# verify backup
ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshot.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| 478dcbd4 | 73771 | 1704 | 3.8 MB |
+----------+----------+------------+------------+
# backup, externally (ideal)
## snapshot.db
## certificates at /etc/kubernetes/pki/etcd
Restore via etcdctl restore
creates a new etcd data directory restore all nodes using the same snapshot overwrites member id and cluster id — new cluster new servers must have the same IP as old ones, for restore to succeed new etcd data dirs each node specifiy cluster IPs, token start new cluster with the new data dir Update a cluster via kubeadm
TODO: missing diagram Use kubeadm to update 1. control plane, 2. kubelet, kubectl
master
sudo su
apt-mark unhold kubeadm
apt install -y kubeadm=1.18.9-00
kubeadm upgrade plan
# COMPONENT CURRENT AVAILABLE
# Kubelet 3 x v1.17.8 v1.18.9
# Upgrade to the latest stable version:
# COMPONENT CURRENT AVAILABLE
# API Server v1.17.12 v1.18.9
# Controller Manager v1.17.12 v1.18.9
# Scheduler v1.17.12 v1.18.9
# Kube Proxy v1.17.12 v1.18.9
# CoreDNS 1.6.5 1.6.7
# Etcd 3.4.3 3.4.3-0
# You can now apply the upgrade by executing the following command:
# kubeadm upgrade apply v1.18.9
kubeadm upgrade apply v1.18.9
## downloads images and swaps them with minimal downtime
## might mess up k8s config file, use
kubectl --kubeconfig .kube/config get no
apt-mark unhold kubelet kubectl
apt install -y kubelet=1.18.9-00
apt install -y kubectl=1.18.9-00
kubectl --kubeconfig .kube/config version --short
# Client Version: v1.18.9
# Server Version: v1.18.9
kubectl --kubeconfig .kube/config get no
# NAME STATUS ROLES AGE VERSION
# ip-10-0-1-101 Ready master 3h15m v1.18.9
# ip-10-0-1-102 Ready <none> 3h15m v1.17.8
# ip-10-0-1-103 Ready <none> 3h15m v1.17.8
repeat kubelet upgrade on all worker nodes
sudo su
apt-mark unhold kubelet && apt install -y kubelet=1.18.9-00
on master
kubectl --kubeconfig .kube/config get no
# NAME STATUS ROLES AGE VERSION
# ip-10-0-1-101 Ready master 3h19m v1.18.9
# ip-10-0-1-102 Ready <none> 3h18m v1.18.9
# ip-10-0-1-103 Ready <none> 3h18m v1.18.9
Cluster communications Pod and node Missing diagrams comms done by a container network interface (cni)
# process 8149 from docker ps; docker inspect --format '{{ State.Pid }}'
sudo nsenter -t 8149 -n ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP group default
link/ether aa:04:93:82:cc:90 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.244.79.10/32 scope global eth0
valid_lft forever preferred_lft forever
# to note:
# eth0 IN THE POD -> if9 interface
# inet 10.244.79.10/32
should map to an interface via ifconfig
Container Network Interface TODO: Missing diagram plugin options:
calico romana flannel weave net more... Once installed, a network agent is installed per node, ties to the CNI interface, kubelet is notified (set network plugin flag = cni) kubeadm init --pod-network-cidr=10.244.0.0/16 >> diffeent per pluginThe container runtime calls cni executable to add/remove instance from the interface
cni
creates IP address and assign to pod IP address management (available) over time Service Networking TODO: Missing diagram Communication outside the cluster (internet?)
Services
Simplify locating critical infrastructure components, move or create additional replicas Provides one virtual interface; evenly distributed and assigned to pods Pods' IP addresses change but from the outside all goes via the same Network interface Node Port service apiVersion: v1
kind: Service
metadata:
name: nginx-nodeport
spec:
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30080
selector:
app: nginx
ClusterIPService created by default on cluster creation.
kubectl get service -o yaml
apiVersion: v1
items:
- apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2020-09-29T06:58:42Z"
labels:
component: apiserver
provider: kubernetes
name: kubernetes
namespace: default
resourceVersion: "148"
selfLink: /api/v1/namespaces/default/services/kubernetes
uid: dd606201-09e0-450b-b551-521987d97dcf
spec:
clusterIP: 10.96.0.1
ports:
- name: https
port: 443
protocol: TCP
targetPort: 6443
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
- apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2020-09-29T09:20:18Z"
labels:
run: nginx
name: nginx
namespace: default
resourceVersion: "21051"
selfLink: /api/v1/namespaces/default/services/nginx
uid: 4c817d34-9d1b-4519-8a97-d5a6ce71c24b
spec:
clusterIP: 10.103.151.135
externalTrafficPolicy: Cluster
ports:
- nodePort: 31297
port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
kind: List
metadata:
resourceVersion: ""
selfLink: ""
service is created, notifies all kubeproxy agents
kubeproxy not an actual proxy, controller that keeps track of endpoints and update IP tables for traffic routing
endpoints are API objects created automatically with the services, has a cache of the IPs of the pods in that service.
redirects traffic to another pod in that service using iptables root@f2c3d18a641c:~# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7d
nginx NodePort 10.103.151.135 <none> 80:31297/TCP 6d22h
root@f2c3d18a641c:~# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 172.31.31.60:6443 7d
nginx 10.244.79.12:80 6d22h
# iptables-save | grep KUBE | grep nginx
-A KUBE-SERVICES ! -s 10.244.0.0/16 -d 10.103.151.135/32 -p tcp -m comment --comment "default/nginx: cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ
Ingress rules and load balancer load balancer will help route traffic if any node goes down (no downtime)
LoadBalancer type service, can be provisioned automatically instead of a Node type
Creating a load balancer service
kubectl expose deployment <name> --port 80 --target-port 808 --type LoadBalancer
checking yamlkubectl get services <name> -o yaml
Node Port assigned, SessionAffinity=None (balancer), ingressIP assigned Not aware of pods within each NODE; use IPTables Add annotations to avoid node hoping (and increased latency)
kubectl describe services <name>
kubectl annotate service <name> externalTrafficPolicy=Local
Ingress resource: Operates at the application layer, single point of communication for clients.
Ingress >> App >> Service >> Pod
Ingress controller and ingress resource
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: service-ingress
spec:
rules:
- host:
http:
paths:
...
- host:
http:
paths:
...
- host:
http:
paths:
...
kubectl create -f ingress.yaml
kubectl edit ingress
kubectl describe ingress
Cluster DNS CoreDNS
native solution, flexible DNS server (golang), mem safe executable, DNS over TLS, integrates w etcd and cloud providers, plugin architecture.
kubectl get pods -n kube-system | grep coredns
# coredns-66bff467f8-vckc2 1/1 Running 2 19h
# coredns-66bff467f8-vtz59 1/1 Running 1 5h41m
kubectl get deployments -n kube-system | grep coredns
# coredns 2/2 2 2 7d1h
kubectl get services -n kube-system
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 7d1h
---
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- image: busybox:1.28.4
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
restartPolicy: Always
kubectl create -f busybox.yaml
kubectl get pods
kubectl exec -t busybox -- cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local us-east-1.compute.internal
options ndots:5
kubectl exec -it busybox -- nslookup kubernetes
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
#servicename. namespace. base_domain_name
kubernetes.default.svc.cluster.local
10.96.0.1.default.pod.cluster.local
#pod-IP.namespace.base_domain_name
kubectl exec -it busybox -- nslookup 10-244-194-199.default.pod.cluster.local
kubectl exec -it busybox -- nslookup kube-dns.kube-system.default.pod.cluster.local
check the dns server is reachable within the busybox pod (good for troubleshooting)
Check dns pod
kubectl logs -n kube-system coredns-66bff467f8-vckc2
.:53
[INFO] plugin/reload: Running configuration MD5 = 4e235fcc3696966e76816bcd9034ebc7
CoreDNS-1.6.7
linux/amd64, go1.13.6, da7f65b
headless service, returns single pod IP, instead of a Service
---
apiVersion: v1
kind: Service
metadata:
name: kube-headless
spec:
clusterIP: None
ports:
- port: 80
targetPort: 8080
selector:
app: kubeserve2
Default config is cluster first: Pod inherits configuration from the Node, otherwise cutomize:
custom-dns.yaml
---
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: dns-example
spec:
containers:
- name: test
image: nginx
dnsPolicy: "None"
dnsConfig:
nameservers:
- 8.8.8.8
searches:
- ns1.svc.cluster.local
- my.dns.search.suffix
options:
- name: ndots
value: "2"
- name: edns0
use busybox pod to query dns
kubectl exec -it busybox -- nslookup 10-244-194-200.default.pod.cluster.local
then query resolve to check dns has been configured well
kubectl exec -t dns-exampple -- cat /etc/resolv.conf
nameserver 8.8.8.8
search ns1.svc.cluster.local my.dns.search.suffix
options ndots:2 edns0
Hands on # create an nginx deployment
kubectl --kubeconfig .kube/config run nginx --image=nginx
kubectl --kubeconfig .kube/config get pods
# create a service
kubectl expose deployment nginx --port 80 --type NodePort
kubectl get services
# a pod to check on dns
---
apiVersion: v1
kind: Pod
metadata:
name: busybox
spec:
containers:
- image: busybox:1.28.4
command:
- sleep
- "3600"
name: busybox
restartPolicy: Always
kubectl create -f busybox.yaml
# query dns for nginx
kubectl exec busybox -- nslookup nginx
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: nginx
Address 1: 10.103.132.129 nginx.default.svc.cluster.local
# FQN: nginx.default.svc.cluster.local
Scheduling in Cluster Scheduler determines which node should host a given pod. Rules by default (but customizable)
Does the node have enough hardware resources? Is the node is running out of resources? Is the pod marked as destined to a specific node? Check if the pod and node have a matching selector Is the pod linked to a specific nodePort, is available? Is the pod linked to a specific volume, can be mounted? Does the pod tolerate taints of the node? Does the pod specify node or pod affinity rules? Results in a set of candidate nodes that are prioritized then best one is chosen (round-robin if all the same priority)
Affinity : Scheduling without having to specify selectors, nice to have rules.
Example adding label to nodes
kubectl label node [fc9ccdd4e21c.mylabserver.com](<http://fc9ccdd4e21c.mylabserver.com/>) availability-zone=zone2
kubectl label node [ed092a70c01c.mylabserver.com](<http://ed092a70c01c.mylabserver.com/>) share-type=dedicated
Creating a deployment and setting up affinity to labels (pref-deployment.yaml)
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: pref
spec:
replicas: 5
selector:
matchLabels:
app: pref
template:
metadata:
labels:
app: pref
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
preference:
matchExpressions:
- key: availability-zone
operator: In
values:
- zone1
- weight: 20
preference:
matchExpressions:
- key: share-type
operator: In
values:
- dedicated
containers:
- args:
- sleep
- "99999"
image: busybox
name: main
preferredDuringSchedulingIgnoredDuringExecution: don't affect nodes already running, apply only during schedulinggive more preference to zone than type of node kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox 1/1 Running 3 22h 10.244.194.201 ed092a70c01c.mylabserver.com <none> <none>
dns-example 1/1 Running 1 22h 10.244.194.202 ed092a70c01c.mylabserver.com <none> <none>
nginx-6db489d4b7-rz56v 1/1 Running 2 28h 10.244.79.15 fc9ccdd4e21c.mylabserver.com <none> <none>
pref-646c88c576-58vhm 1/1 Running 0 4m16s 10.244.194.203 ed092a70c01c.mylabserver.com <none> <none>
pref-646c88c576-d2mw2 1/1 Running 0 4m16s 10.244.194.207 ed092a70c01c.mylabserver.com <none> <none>
pref-646c88c576-qmmw4 1/1 Running 0 4m16s 10.244.194.204 ed092a70c01c.mylabserver.com <none> <none>
pref-646c88c576-srz8l 1/1 Running 0 4m16s 10.244.194.205 ed092a70c01c.mylabserver.com <none> <none>
pref-646c88c576-xprgq 1/1 Running 0 4m16s 10.244.194.206 ed092a70c01c.mylabserver.com <none> <none>
pods assigned to node with higher affinity, unless scheduler decides to spread out
Multiple schedulers for multiple pods ---
apiVersion: v1
kind: ServiceAccount
metadata:
name: my-scheduler
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: my-scheduler-as-kube-scheduler
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:kube-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: my-scheduler-as-volume-scheduler
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:volume-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: scheduler
tier: control-plane
name: my-scheduler
namespace: kube-system
spec:
selector:
matchLabels:
component: scheduler
tier: control-plane
replicas: 1
template:
metadata:
labels:
component: scheduler
tier: control-plane
version: second
spec:
serviceAccountName: my-scheduler
containers:
- command:
- /usr/local/bin/kube-scheduler
- --address=0.0.0.0
- --leader-elect=false
- --scheduler-name=my-scheduler
image: chadmcrowell/custom-scheduler
livenessProbe:
httpGet:
path: /healthz
port: 10251
initialDelaySeconds: 15
name: kube-second-scheduler
readinessProbe:
httpGet:
path: /healthz
port: 10251
resources:
requests:
cpu: '0.1'
securityContext:
privileged: false
volumeMounts: []
hostNetwork: false
hostPID: false
volumes: []
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
# "namespace" omitted since ClusterRoles are not namespaced
name: csinode-admin
rules:
- apiGroups: ["storage.k8s.io"]
resources: ["csinodes"]
verbs: ["get", "watch", "list"]
---
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: read-csinodes-global
subjects:
- kind: ServiceAccount
name: my-scheduler # Name is case sensitive
namespace: kube-system
roleRef:
kind: ClusterRole
name: csinodes-admin
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: system:serviceaccount:kubesystem:my-scheduler
namespace: kube-system
rules:
- apiGroups: ["storage.k8s.io"] # "" indicates the core API group
resources: ["csinodes"]
verbs: ["get", "watch", "list"]
---
apiVersion: rbac.authorization.k8s.io/v1
# This role binding allows "jane" to read pods in the "default" namespace.
# You need to already have a Role named "pod-reader" in that namespace.
kind: RoleBinding
metadata:
name: read-csinodes
namespace: kube-system
subjects:
# You can specify more than one "subject"
- kind: User
name: kubernetes-admin # "name" is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
# "roleRef" specifies the binding to a Role / ClusterRole
kind: Role #this must be Role or ClusterRole
name: system:serviceaccount:kube-system:my-scheduler # this must match the name of the Role or ClusterRole you wish to bind to
apiGroup: rbac.authorization.k8s.io
kubectl create -f clusterrole.yaml && kubectl create -f clusterrolebinding.yaml
kubectl create -f role.yaml && kubectl create -f rolebinding.yaml
editing cluster role kubectl edit clusterrole system:kube-scheduler
resourceNames:
- kube-scheduler
- my-scheduler # <------NEW
kubectl create -f myscheduler.yaml
check scheduler is running
kubectl get pods -n kube-system | grep scheduler
kube-scheduler-f2c3d18a641c.mylabserver.com 1/1 Running 3 43h
my-scheduler-5b986674f-w7sc6 1/1 Running 0 2m9s
create a pod assign to default, my-scheduler, or leave empty (default scheduler assigned)
apiVersion: v1
kind: Pod
metadata:
name: annotation-scheduler-type
labels:
name: multischeduler-example
spec:
schedulerName: <default-scheduler | my-scheduler | remove line> # <--- HERE scheduler ?
containers:
- name: pod-with-scheduler-or-not
image: k8s.gcr.io/pause:2.0
The easiest way to know which scheduler created the pod is by looking at metadata name; should match spec.
Resource limits and label selectors for scheduling Taints : Repel work
e.g., Master node No schedule kubectl describe node master-node-name section Taints Tolerations : Permit a taint to potentially schedule on a node
e.g., kube-proxy: kube-ctl get pods kube-proxy-1111 -n namespace -o yaml section tolerations tolerates unschedulable nodes, see toleation effect NoSchedule Priority functions : Assign pods in nodes with most requested resources (optimize number of nodes)
Find nodes capacity with describe in sections Capacity & Allocatable If pod fits, use the node selector to assign kubectl create -f resource-pod.yaml apiVersion: v1
kind: Pod
metadata:
name: resource-pod1
spec:
nodeSelector:
kubernetes.io/hostname: "name-of-node"
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: pod1
resources:
requests:
cpu: 800m
memory: 20Mi #<---- needed mem
If not enough resources in the node, pod will fail with message Insufficient resources, verify via kubect describe pod
Set hard limits on the resources a pod maybe use
apiVersion: v1
kind: Pod
metadata:
name: resource-pod-limit
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
limits: #<--- how much can be used
cpu: 1
memory: 20Mi
with limit, pod may be deployed even if resources exceed node capacity. k8s will terminate a node if needed. Verify kubectl exec -it resource-pod-limit -- top
DaemonSets and Manual Schedules TODO: Add daemonSet pods diagrams A DaemonSet doesn't use the scheduler.
land a pod per node
Good fit: Run exactly one replica of a pod in every node, e.g., kube-proxy, calico-node
Run pod in each node Make sure replicas running immediately, recreates automatically Create a daemonSet to monitor SSD
# label the target node
kubectl label node ed092a70c01c.mylabserver.com disk=ssd
# create daemon set
kubectl create -f ssd-monitor.yaml
# check daemonsets and related pod
kubectl get daemonsets
kubectl get pod -o wide
# add label to other nodes and daemonSet will create new pods
kubectl label node fc9ccdd4e21c.mylabserver.com disk=ssd
# remove/change label; will make daemonset terminate ssd-monitor pod
kubectl label node fc9ccdd4e21c.mylabserver.com disk-
kubectl label node ed092a70c01c.mylabserver.com disk=hdd --overwrite
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ssd-monitor
spec:
template:
metadata:
labels:
app: ssd-monitor
spec:
nodeSelector:
disk: ssd
containers:
- name: main
image: linuxacademycontent/ssd-monitor
selector:
matchLabels:
app: ssd-monitor
Scheduler events Pod: check events section withkubectl describe pods kube-scheduler-f2c3d18a641c.mylabserver.com -n kube-system
Check Events: kubectl get event -n kube-system -w Check Log: kubectl logs kube-scheduler-f2c3d18a641c.mylabserver.com -n kube-system More logs at /var/log/pods/kube-system_* Hands on Taint node to repel work
kubectl taint node ip-node2 node-type=prod:NoSchedule && kubectl describe node ip-node2
Taints: node-type=prod:NoScheduleSchedule pod to dev environment kubectl create -f dev-pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: dev-pod
labels:
app: busybox
spec:
containers:
- name: dev
image: busybox
command: ['sh', 'c', 'echo Hello K8s! && sleep 3600']
Allow a pod to be scheduled to production
Creat a deployment kubectl -f prod-deploymet.yaml; apiVersion: apps/v1
kind: Deployment
metadata:
name: prod
spec:
replicas: 1
selector:
matchLabels:
app: prod
template:
metadata:
labels:
app: prod
spec:
containers:
- args: [sleep, "3600"]
image: busybox
name: main
tolerations:
- key: node-type
operator: Equal
value: prod
effect: NoSchedule
Verify pod schedule and check toleration
kubeclt scale deployment/prod --replicas=3kubeclt get pods prod-7654d444bc-slzlx -o yaml and look fortolerations:
- effect: NoSchedule
key: node-type
operator: Equal
value: prod
Deploying Applications apiVersion: apps/v1
kind: Deployment
metadata:
name: kubeserve
spec:
replicas: 3
selector:
matchLabels:
app: kubeserve
template:
metadata:
name: kubeserve
labels:
app: kubeserve
spec:
containers:
- image: linuxacademycontent/kubeserve:v1
name: app
kubectl create -f kubeserve-deployment.yaml --record
--record: store CHANGE-CAUSE in the rollout history (see below)check status of deployment
kubectl rollout status deployments kubeserve && kubectl get pods
Waiting for deployment "kubeserve" rollout to finish: 0 of 3 updated replicas are available...
Waiting for deployment "kubeserve" rollout to finish: 1 of 3 updated replicas are available...
Waiting for deployment "kubeserve" rollout to finish: 2 of 3 updated replicas are available...
deployment "kubeserve" successfully rolled out
kubeserve-6b7cdb8ddc-4hc2b 1/1 Running 0 93s
kubeserve-6b7cdb8ddc-v5g48 1/1 Running 0 93s
kubeserve-6b7cdb8ddc-vnx8f 1/1 Running 0 93s
Pod name comes from the hash val of pod template replica set and deployment ReplicaSet created automatically to manage these pods kubectl get replicasetskubeserve-6b7cdb8ddc 3 3 3 3m58s Scale via kubectl scale deployment kubeserve --replicas=5
kubectl expose deployment kubeserve --port 80 --target-port 80 --type NodePort
service/kubeserve exposed
# app exposed the internet
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubeserve NodePort 10.111.181.169 <none> 80:31347/TCP 42s
Updating app
Change the spec to slow app deployment and visualize better
kubectl patch deployment kubeserve -p '{"spec": {"minReadySeconds":10}}'
deployment.apps/kubeserve patched
Method 1
Update the yaml file, e.g., image version, and kubectl apply -f kubeserve-deployment.yaml
kubectl describe deployments | grep linuxacademycontent
Image: linuxacademycontent/kubeserve:v2
kubectl replace -f kubeserve-deployment.yaml (will fail if deployment doesn't exist)
Method 2 (preferred)
Rolling update ( no downtime)
kubectl set image deployments/kubeserve app=linuxacademycontent/kubeserve:v2 --v 6
verbose level 6 will replace all pod images with v2 gradually creates new replicaSet As new replicaSet pods aree created, terminates pods in the old replicaSet kubectl get replicasets
NAME DESIRED CURRENT READY AGE
kubeserve-6b7cdb8ddc 0 0 0 46m
kubeserve-7fd7b74ffd 3 3 3 31m
kubectl describe replicaset kubeserve-7fd7b74ffd
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 32m replicaset-controller Created pod: kubeserve-7fd7b74ffd-n98tm
Normal SuccessfulCreate 31m replicaset-controller Created pod: kubeserve-7fd7b74ffd-q86n2
Normal SuccessfulCreate 31m replicaset-controller Created pod: kubeserve-7fd7b74ffd-p9p26
Normal SuccessfulDelete 10m replicaset-controller Deleted pod: kubeserve-7fd7b74ffd-p9p26
Normal SuccessfulDelete 10m replicaset-controller Deleted pod: kubeserve-7fd7b74ffd-q86n2
Normal SuccessfulDelete 10m replicaset-controller Deleted pod: kubeserve-7fd7b74ffd-n98tm
Normal SuccessfulCreate 6m58s replicaset-controller Created pod: kubeserve-7fd7b74ffd-cnzgg
Normal SuccessfulCreate 6m45s replicaset-controller Created pod: kubeserve-7fd7b74ffd-ghthr
Normal SuccessfulCreate 6m32s replicaset-controller Created pod: kubeserve-7fd7b74ffd-ckmj
Undo a deployment
kubectl rollout undo deployments kubeserve
deployment has a revision history in the underlying replicasets, therefore is preferred to patching the current deployment (method 1)
# rollback last deployment
kubectl rollout history deployment kubernetes
deployment.apps/kubeserve
REVISION CHANGE-CAUSE
3 kubectl create --filename=kubeserve-deployment.yaml --record=true
4 kubectl create --filename=kubeserve-deployment.yaml --record=true
# rollback to specific version
kubectl rollout undo deployments kubeserve --to-revision=3
Pause a rollout deployment kubectl rollout pause deployment kubeserve leaving new and old pods (canary release), the command kubectl rollout resume will unpause the rollout.
Configuring for High Available and Scalable applications TODO: configuration data passing to apps minimize opportunity for errors when deploying apps prevent faulty versions from being released minReadySeconds property: How many secs a pod should be in state Ready before considered as available — deters rollout until available
readinessProbe = success: pod will receive client requests
Check every second until gets success message
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubeserve
spec:
replicas: 3
selector:
matchLabels:
app: kubeserve
template:
metadata:
name: kubeserve
labels:
app: kubeserve
spec:
containers:
- image: linuxacademycontent/kubeserve:v1
name: app
readinessProbe:
periodSeconds: 1
httpGet:
path: /
port: 80
kubectl apply -f readiness.yaml
kubectl rollout status deployment kubeserve
deployment "kubeserve" successfully rolled out
# if doesn't pass the readiness probe expect 'progress deadline exceeded' error
How to pass configuration options Method 1: Env variables
Commonly use store stuff like keys, passwords use a ConfigMap and pass to container via environment variable May useSecret as environment variable Just update configmap or secret, instead of rebuilding the image create a configmap from literal
kubectl create configmap appconfig --from-literal=key1=value1 --from-literal=key2=value2
passing config map into Pod
apiVersion: v1
kind: Pod
metadata:
name: configmap-pod
spec:
containers:
- name: app-container
image: busybox:1.28.4
command: ["sh", "-c", "echo $(MY_VAR) && sleep 3600"]
env:
- name: MY_VAR
valueFrom:
configMapKeyRef:
name: appconfig
key: key1
kubectl logs configmap-pod # retrieve via logs
$~ value1Method 2: Mounted volume
apiVersion: v1
kind: Pod
metadata:
name: configmap-pod
spec:
containers:
- name: app-container
image: busybox:1.28.4
command: ["sh", "-c", "echo $(MY_VAR) && sleep 3600"]
volumeMounts:
- name: configmapvolume
mountPath: /etc/config
volumes:
- name: configmapvolume
configMap: # <-------- mark volume as a configmap
name: appconfig
kubectl exec configmap-pod -- ls /etc/config
$~ key1
$~ key2
kubectl exec configmap-pod -- cat /etc/config/key1
$~ value1
Method 3: Secret
for sensitive data use Secret
apiVersion: v1
kind: Secret
metadata:
name: appsecret
stringData:
cert: value
key: value
apiVersion: v1
kind: Pod
metadata:
name: secret-pod
spec:
containers:
- name: app-container
image: busybox:1.28.4
command: ["sh", "-c", "echo $(MY_VAR) && sleep 3600"]
env:
- name: MY_CERT
valueFrom:
secretKeyRef:
name: appsecret
key: cert
kubectl exec -it secret-pod -- sh
echo $MY_CERT
$~ valMethod 4: Secrets in a volume
apiVersion: v1
kind: Pod
metadata:
name: secret-mount-pod
spec:
containers:
- name: app-container
image: busybox:1.28.4
command: ["sh", "-c", "echo $(MY_VAR) && sleep 3600"]
volumeMounts:
- name: secretvolume
mountPath: /etc/cert
volumes:
- name: secretvolume
secret:
secretName: appsecret
kubectl exec secret-mount-pod -- ls /etc/cert
$~ cert
$~ keySelf-healing applications Reduce the need to monitor for errors, Take error prone servers or application out of the cluster via ReplicaSet => No downtime, create replicas in healthy nodes e.g, anything labeled tier=frontend will be picked up by the replicaSet automatically
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myreplicaset
labels:
app: app
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: main
image: linuxacademycontent/kubeserve
apiVersion: v1
kind: Pod
metadata:
name: pod1
labels:
tier: frontend
spec:
containers:
- name: main
image: linuxacademycontent/kubeserve
kubectl create -f replicaset.yaml
kubeclt apply -f pod-replica.yaml && kubeclt get pods -o wide
# the pod is terminated as it is managed by the replicaset and there are already 3
pod1 0/1 Terminating 0
The ReplicaSet manages the pod but ideally we should be using a Deployment (adds deploying, scaling, updating)
Remove a pod from a replicaSet by changing its label
StatefulSet Pods are unique, don't replace instead recreate an identical pod when needed.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
service is headless, as every pod is unique (specific traffic to specific pods) volumeClaimTemplate; each pod needs its own storage kubectl get statefulsets
kubectl describe statefulsets
Hands on apiVersion: apps/v1
kind: Deployment
metadata:
name: kubeserve
spec:
replicas: 3
selector:
matchLabels:
app: kubeserve
template:
metadata:
name: kubeserve
labels:
app: kubeserve
spec:
containers:
- image: linuxacademycontent/kubeserve:v1
name: app
Create a deployment (record), check status, and verify vesion kubectl create -f deployment.yaml --record
kubectl rollout status deployments kubeserve
$ deployment "kubeserve" successfully rolled out
kubectl describe deployments/kubeserve | grep Image
$ Image: linuxacademycontent/kubeserve:v1
Make highly available by scaling up kubectl scale deployment/kubeserve --replicas=5 && kubectl get pods
Make it accessible via Service, NodePort kubectl expose deployment kubeserve --port 80 --target-port 80 --type NodePort && kubectl get services
on separate terminal while true; do curl <http://node-port-ip>; done;
# on main terminal, switch image to v2
kubectl set image deploymens/kubeserve app=linuxacademycontent/kubeserve:v2 --v 6
deployment.extensons/kubeserve image updated
# old and new replicasets
kubectl get replicasets
NAME DESIRED CURRENT READY AGE
kubeserve-5589d5cb58 5 5 5 4m4s
kubeserve-968646c97 0 0 0 23m
kubectl get pods
NAME READY STATUS RESTARTS AGE
kubeserve-5589d5cb58-59pds 1/1 Running 0 5m4s
kubeserve-5589d5cb58-94vxx 1/1 Running 0 4m59s
kubeserve-5589d5cb58-dcsdx 1/1 Running 0 5m4s
kubeserve-5589d5cb58-n7nnv 1/1 Running 0 4m59s
kubeserve-5589d5cb58-tqxmp 1/1 Running 0 5m4s
# rollout versions if needed
kubectl rollout history deployment kubeserve
deployment.extensions/kubeserve
REVISION CHANGE-CAUSE
0
1
Managing Data Persistent volumes Storage that is accessible even if the pods are gone and can be reassigned dynamically
gcloud compute disks create mongodb --size=10GB --zone=us-central1-c
without persistent volumes (just storage)
apiVersion: v1
kind: Pod
metadata:
name: mongodb
spec:
volumes:
- name: mongodb-data
gcePersistentDisk:
pdName: mongodb
fsType: ext4
containers:
- image: mongo
name: mongodb
volumeMounts:
- name: mongodb-data
mountPath: /data/db
ports:
- containerPort: 27017
protocol: TCP
kubectl create -f mongodb-pod.yaml && kubectl get pods
insert something via shell kubectl exec -it mongodb mongo
use mystore
db.hello.insert({name: 'hello'})
WriteResult({ "nInserted" : 1 })
db.hello.find()
{ "_id" : ObjectId("5f85864fa02484221b37a386"), "name" : "hello" }
exit
then delete and drain node kubectl delete pod mongodb && kubectl drain gke-kca-lab-default-pool-eb962a64-c7q9
recreate from same yaml and retrieve data with exec on the new node (The data persists)
{ "_id" : ObjectId("5f85864fa02484221b37a386"), "name" : "hello" }
Using persistent volumes
apiVersion: v1
kind: PersistentVolume
metadata:
name;: mongodb-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
gcePersistentDisk:
pdName: mongodb
fsType: ext4
kubectl create -f mongo-persistentvolume.yaml
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 10Gi RWO,ROX Retain Available
Access modes Whether a PersistentVolume can be accessed by multiple nodes concurrently:
RWO: Read write once, only one node at a time ROX: Read only many, multiple nodes can mount for reading RWX: Read write many, multiple nodes can read and write Read for the node, not the pod! and apply just one mode at a time
Persistent Volume Claims Request for use by a pod, reserve existing (provisioned) storage for use by a pod
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongodb-pvc
spec:
resources:
requests:
storage: 1Gi
accessModes:
- ReadWriteOnce
storageClassName: ""
kubectl create -f pvc.yaml
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mongodb-pvc Bound mongodb-pv 10Gi RWO,ROX 8s
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 10Gi RWO,ROX Retain Bound default/mongodb-pvc 14m
Verify status has changed to Bound for both pv and pvc
Persistent Volume claims diagram apiVersion: v1
kind: Pod
metadata:
name: mongodb
spec:
volumes:
- name: mongodb-data
persistentVolumeClaim:
claimName: mongodb-pvc
containers:
- image: mongo
name: mongodb
volumeMounts:
- name: mongodb-data
mountPath: /data/db
ports:
- containerPort: 27017
protocol: TCP
kubectl create -f pvc-pod.yaml && kubectl describe pod mongodb
...
Volumes:
mongodb-data:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: mongodb-pvc
ReadOnly: false
kubectl exec -it mongodb mongo => use mystore => db.hello.find() => {...}
kubectl delete pod mongodb && kubectl delete pvc mongodb-pvc
and since persistentVolumeReclaimPolicy = Retain in pv.yaml (other options Recycle, Delete) the volume is kept and status is Released
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 10Gi RWO,ROX Retain Released default/mongodb-pvc 26m
Storage Objects Protects against data loss when a PersistentVolumeClaim is bound. StorageObject prevents pvc from being removed prematurely. If a pv is deleted and pvc are still using it, the PV removal is postponed
kubectl describe pv mongodb-pv
Name:
mongodb-pv
Labels: failure-domain.beta.kubernetes.io/region=us-central1
failure-domain.beta.kubernetes.io/zone=us-central1-c
Annotations: pv.kubernetes.io/bound-by-controller: yes
Finalizers: [kubernetes.io/pv-protection] # <----- removal is postponed until the PVC is no longer actively
StorageClass:
Status: Released
Claim: default/mongodb-pvc
Reclaim Policy: Retain
Access Modes: RWO,ROX
VolumeMode: Filesystem
Capacity: 10Gi
Node Affinity:
Required Terms:
Term 0: failure-domain.beta.kubernetes.io/zone in [us-central1-c]
failure-domain.beta.kubernetes.io/region in [us-central1]
Message:
Source:
Type: GCEPersistentDisk (a Persistent Disk resource in Google Compute Engine)
PDName: mongodb
FSType: ext4
Partition: 0
ReadOnly: false
Events: <none>
kubectl describe pvc
Name: mongodb-pvc
Namespace: default
StorageClass:
Status: Pending
Volume:
Labels: <none>
Annotations: <none>
Finalizers: [kubernetes.io/pvc-protection] # <---removal is postponed until the PVC is no longer actively
Finalizers: [kubernetes.io/pv-protection]:
A deleted pvc will remain in state terminating until the pod is deleted to Prevents data loss Or use StorageClass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
kubectl -f create sc-f.yaml && kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
fast kubernetes.io/gce-pd Delete Immediate false 8s
standard (default) kubernetes.io/gce-pd Delete Immediate true 116m
update pvc.yaml
...
accessModes:
- ReadWriteOnce
storageClassName: "fast" #<---- update this
kubectl create -f pvc.yaml && kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mongodb-pvc Bound pvc-7b2d28a2-ee88-4a2e-8718-81b72ac668a3 1Gi RWO fast 6s
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 10Gi RWO,ROX Retain Released default/mongodb-pvc 48m
pvc-7b2d28a2-ee88-4a2e-8718-81b72ac668a3 1Gi RWO Delete Bound default/mongodb-pvc fast 76s
provisioned already with storageClass=fast Different kinds of storage class; including FileSystem local storage and emptyDir available. gitRepo volumes are deprecatedApplications with Persistence Storage apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: kubeserve-pvc
spec:
resources:
requests:
storage: 100Mi
accessModes:
- ReadWriteOnce
storageClassName: "fast"
kubectl create -f storageclass-fast.yaml && kubectl create -f kubeserve-pvc.yaml
kubectl get sc && kubectl get pvc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
fast kubernetes.io/gce-pd Delete Immediate false 37s
standard (default) kubernetes.io/gce-pd Delete Immediate true 137m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
kubeserve-pvc Bound pvc-6a28b319-90dd-4d2c-a210-1fec1cef20a2 1Gi RWO fast 36s
# automatically provisioned storage
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-6a28b319-90dd-4d2c-a210-1fec1cef20a2 1Gi RWO Delete Bound default/kubeserve-pvc fast 78s
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubeserve
spec:
replicas: 1
selector:
matchLabels:
app: kubeserve
template:
metadata:
name: kubeserve
labels:
app: kubeserve
spec:
containers:
- env:
- name: app
value: 1
image: linuxacademycontent/kubeserve:v1
name: app
volumeMounts:
- mountPath: /data
name: volume-data
volumes:
- name: volume-data
persistentVoumeClaim:
claimName: kubeserve-pvc
TODO: diagram PV, PVC, SC Hands on 1. create a PersistentVolume
apiVersion: v1
kind: PersistentVolume
metadata:
name: redis-pv
spec:
storageClassName: ""
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
kubectl create -f redis-pv.yaml
2. create PersistentVolumeClaim
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: redisdb-pvc
spec:
storageClassName: ""
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
kubectl create -f redis-pvc.yaml
3. Create a pod image with a mounted volume to mount /data
apiVersion: v1
kind: Pod
metadata:
name: redispod
spec:
containers:
- image: redis
name: redisdb
volumeMounts:
- name: redis-data
mountPath: /data
ports:
- containerPort: 6379
protocol: TCP
volumes:
- name: redis-data
persistentVolumeClaim:
claimName: redisdb-pvc
kubectl create -f redispod.yaml
4. Write some data in the containers
kubectl exec -it redispod -- redis-cli
SET server:name: "redis server"
GET server:name
"redis server"
QUIT
5. Delete pod and create redispod2
kubeclt delete pod redispod
# edit name in redispod.yam to redispod2
kubectl create -f redispod.yaml
6. Verify data persists
kubectl exec -it redispod2 -- redis-cli
127.0.0.1:6379> GET server:name
"redis server"
QUIT
Security Primitives When accessing the API, requests are evaluated:
Normal user: Private key, user store, usr, pwd. — can't be added via API call ServiceAccount: Manage identity request, they use a Secret used for API authenticationkubectl get serviceaccounts
NAME SECRETS AGE
default 1 16d
# create a new sa
kubectl create sa jenkins
serviceaccount/jenkins created
# see internals including secrets
kubectl get sa jenkins -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: "2020-10-15T08:11:13Z"
name: jenkins
namespace: default
resourceVersion: "303206"
selfLink: /api/v1/namespaces/default/serviceaccounts/jenkins
uid: bb1d17cd-9700-4ea8-a9fb-32b64f12ed7b
secrets:
- name: jenkins-token-4fpvn
# get secret used to authenticate to APO
kubectl get secret jenkins-token-4fpvn
NAME TYPE DATA AGE
jenkins-token-4fpvn kubernetes.io/service-account-token 3 68s
Every new pod will be assigned to the default ServiceAccount unless specified otherwise
kubectl get pod web-pod -o yaml | grep serviceAccount serviceAccount: default serviceAccountName: default
Create a new pod with a specific ServiceAccount
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
serviceAccountName: 'jenkins' # <----- add this
containers:
- image: busybox:1.28.4
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
restartPolicy: Always
kubectl get pods busybox -o yaml | grep serviceAccountserviceAccountName: jenkins
Check location of cluster and credentials via kubectl config view or at ~/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: <https://172.31.31.60:6443> #<------- location (ip-for-master)
name: kubernetes
contexts:
- context:
cluster: kubernetes #<---------- context
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
Allow a specific username to access the cluster remotely (not the master, not recommended in prod)
kubectl config set-credentials joe --username=joe --password=passwordcorrect way: generate a public certificate with cfssl see https://kubernetes.io/docs/concepts/cluster-administration/certificates/
copy /etc/kubernetes/pki/ca.crt to remote server via scp
on remoter server kubectl config set-cluster kubernetes --server=https:/ip-for-master:6443 --certificate-authoritaty=ca.crt --embed-certs=true
on remote server kubectl config set-credentials chad --username=joe --password=password
on remote server, create new context and use it kubectl config set-context kubernetes --cluster=kubernetes --user=chad --namespace=defaultkubectl config use-context kubernetes
on remote server, verify via kubectl get nodes
Authentication and Authorization Authorization: What users are allowed to do, configured via RBAC (Role based access control)
Roles* and ClusterRoles+: What can be performed in which resouceRoleBindings* and ClusterRoleBindings+ : Who can do itnamespace level cluster level apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: service-reader
namespace: web
rules:
- apiGroups: [""]
resources: ["services"]
verbs: ["get", "list"]
kubectl create namespace web && kubectl create -f role.yamlkubectl create rolebinding test --role=service-reader --serviceaccount=web:defaut -n web
rolebinding can bind the role to more than one serviceAccount, user, group
list the services in the web namespace, from the default namespace
separate console kubectl proxy main console curl localhost:8001/api/v1/namespaces/web/services
{
"kind": "ServiceList",
"apiVersion": "v1",
"metadata": {
"selfLink": "/api/v1/namespaces/web/services",
"resourceVersion": "321662"
},
"items": []
}root@f2c3d18a641c:/home/cloud_user#
ClusterRole for viewing persistentVolumes
cat curl-pod
apiVersion: v1
kind: Pod
metadata:
name: curlpod
namespace: web
spec:
containers:
- image: tutum/curl
command: ["sleep", "999999"]
name: main
- image: linuxacademycontent/kubectl-proxy
name: proxy
restartPolicy: Always
kubectl create clusterrole pv-reader --verb=get,list --resource=persistentvolumes &&
kubectl create clusterrolebinding pv-test --clusterrole=pv-reader --serviceaccount=web:default
clusterrole.rbac.authorization.k8s.io/pv-reader created
clusterrolebinding.rbac.authorization.k8s.io/pv-test created
# access at the cluster level
kubectl create -f curl-pod.yaml
kubectl get pods -n web
NAME READY STATUS RESTARTS AGE
curlpod 2/2 Running 0 106s
kubectl exec -it curlpod -n web -- sh
~ curl localhost:8001/api/v1/persistentvolumes
{
"kind": "PersistentVolumeList",
"apiVersion": "v1",
"metadata": {
"selfLink": "/api/v1/persistentvolumes",
"resourceVersion": "324617"
},
"items": []
}#
Can access the cluster level roles with clusterRole and clusterRoleBinding
Network policies Govern how pods communicate with each other (default is open and accessible), matched by label selectors or namespace
ingress rules: who can access the pod egress rules: what pods can use access (may use block range of IP) Plugin is needed, but calico already has it. Other option is canal.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all
spec:
podSelector: {}
policyTypes:
- Ingress
kubectl create -f deny-all-np.yaml
kubectl run nginx --image=nginx --replicas=2
kubectl expose deployment nginx --port=80
kubectl run busybox --rm -it --image=busybox -- /bin/sh
# in the busybox pod
~ wget --spider --timeout=1 nginx
Connecting to nginx (10.103.197.57:80) #<--- can resolve nginx to 10.103... OK
wget: download timed out #<--- has been denied by net policy OK
2 pods talking to each other via NetworkPolicy (pod selector)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: db-netpolicy
spec:
podSelector:
matchLabels:
app: db
ingress:
- from:
- podSelector:
matchLabels:
app: web #<--- pods with app=web can talk to app=db pods using port 5432
ports:
- port: 5432
using a namespace selector
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ns-netpolicy
spec:
podSelector:
matchLabels:
app: db
ingress:
- from:
- namespaceSelector: #<--- pods within namespace web, can access pod wih app=db
matchLabels:
tenant: web
ports:
- port: 5432
using IP block specification
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ipblock-netpolicy
spec:
podSelector:
matchLabels:
app: db
ingress:
- from:
- ipBlock:
cidr: 192.168.1.0/24
kubectl get netpol
egress policy
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: egress-netpolicy
spec:
podSelector:
matchLabels:
app: web # <--- web can communicate wit pods labeled db on 5432
egress: #<---
- to: #<---
- podSelector:
matchLabels:
app: db
ports:
- port: 5432
TLS Certificates CA used to generate a TLS certificate and authentica with the API server.
CA certificate bundle auto mounted into pods with default service account to /var/run/secrets/kubernetes.io/serviceaccount
kubectl exec nginx -- ls /var/run/secrets/kubernetes.io/serviceaccount
ca.crt
namespace
token
Generate a CSR (Certificate signing request) {
"CN": "my-pod.my-namespace.pod.cluster.local",
"hosts": [
"172.168.0.24",
"10.0.34.2",
"my-svc.my-namespace.svc.cluster.local",
"my-pod.my-namespace.pod.cluster.local"
],
"key": {
"algo": "ecdsa",
"size": 256
}
}
# install
wget <https://pkg.cfssl.org/R1.2/cfssl_linux-amd64> <https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64>
chmod +x cfssl*
mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
mv cfssl_linux-amd64 /usr/local/bin/cfssl
cfssl version
$~ Version: 1.2.0
$~ Revision: dev
$~ Runtime: go1.6
# generate
cfssl genkey ca-csr.json | cfssljson -bare server
ls server*
$~ server.csr
$~ server-key.pem
# create k8s csr object, note command line substition in request
cat <<EOF | kubectl create -f -
apiVersion: certificates.k8s.io/v1beta1
kind: CertificateSigningRequest
metadata:
name: pod-csr.web
spec:
signerName: kubernetes.io/kube-apiserver-client
groups:
- system:authenticated
request: $(cat server.csr | base64 | tr -d '\\n')
usages:
- digital signature
- key encipherment
- server auth
EOF
$~ certificatesigningrequest.certificates.k8s.io/pod-csr.web created
Verify CSR object; pending state until admin approves kubectl get pod-csr.web
NAME AGE SIGNERNAME REQUESTOR CONDITION
pod-csr.web 4m kubernetes.io/kube-apiserver-client kubernetes-admin Pending
kubectl describe pod-csr.web
Name: pod-csr.web
Labels: <none>
Annotations: <none>
CreationTimestamp: Tue, 20 Oct 2020 04:04:45 +0000
Requesting User: kubernetes-admin
Signer: kubernetes.io/kube-apiserver-client
Status: Pending
Subject:
Common Name: my-pod.my-namespace.pod.cluster.local
Serial Number:
Subject Alternative Names:
DNS Names: my-svc.my-namespace.svc.cluster.local
my-pod.my-namespace.pod.cluster.local
IP Addresses: 172.168.0.24
10.0.34.2
Events: <none>
kubectl certificate approve pod-csr.web
pod-csr.web 6m15s kubernetes.io/kube-apiserver-client kubernetes-admin Approved
kubectl get csr pod-csr.web -o yaml
apiVersion: certificates.k8s.io/v1beta1
kind: CertificateSigningRequest
metadata:
creationTimestamp: "2020-10-20T04:04:45Z"
managedFields:
- apiVersion: certificates.k8s.io/v1beta1
fieldsType: FieldsV1
fieldsV1:
f:spec:
f:groups: {}
f:request: {}
f:signerName: {}
f:usages: {}
f:status:
f:conditions: {}
manager: kubectl
operation: Update
time: "2020-10-20T04:10:52Z"
name: pod-csr.web
resourceVersion: "350881"
selfLink: /apis/certificates.k8s.io/v1beta1/certificatesigningrequests/pod-csr.web
uid: b8823cac-3afb-4547-a217-46df2757b92e
spec:
groups:
- system:masters
- system:authenticated
request: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURSBSRVFVRVNULS0tLS0KTUlJQllqQ0NBUWdDQVFBd01ERXVNQ3dHQTFVRUF4TWxiWGt0Y0c5a0xtMTVMVzVoYldWemNHRmpaUzV3YjJRdQpZMngxYzNSbGNpNXNiMk5oYkRCWk1CTUdCeXFHU000OUFnRUdDQ3FHU000OUF3RUhBMElBQkhrOG41OEU0eHJuCnh6NU9FcENLRExUSHZiaW1NaUZ0anNLL2NPcVpJTUtnQnlhamVIcDBmOVZrZEJPM09hby9RbTlMaHBYcU5qVGoKZVhWN1pKOEtOclNnZGpCMEJna3Foa2lHOXcwQkNRNHhaekJsTUdNR0ExVWRFUVJjTUZxQ0pXMTVMWE4yWXk1dAplUzF1WVcxbGMzQmhZMlV1YzNaakxtTnNkWE4wWlhJdWJHOWpZV3lDSlcxNUxYQnZaQzV0ZVMxdVlXMWxjM0JoClkyVXVjRzlrTG1Oc2RYTjBaWEl1Ykc5allXeUhCS3lvQUJpSEJBb0FJZ0l3Q2dZSUtvWkl6ajBFQXdJRFNBQXcKUlFJZ01aODZGWXpQcTQ5VDZoYTFFaXRrZWFNbUJzMXQ2bmcrVzlGTlhNb1k0VFFDSVFDZU01NlppVmJ2UVhrVAoyOWQwWllua05zZ09pR3Z3ZDRvdjRGT2NmQ1dmT3c9PQotLS0tLUVORCBDRVJUSUZJQ0FURSBSRVFVRVNULS0tLS0K
signerName: kubernetes.io/kube-apiserver-client
usages:
- digital signature
- key encipherment
- server auth
username: kubernetes-admin
status:
conditions:
- lastUpdateTime: "2020-10-20T04:10:52Z"
message: This CSR was approved by kubectl certificate approve.
reason: KubectlApprove
type: Approved
retrieve certificate back
kubectl get csr pod-csr.web -o jsonpath='{.spec.request}' | base64 --decode > server.crt
-----BEGIN CERTIFICATE REQUEST-----
MIIBYjCCAQgCAQAwMDEuMCwGA1UEAxMlbXktcG9kLm15LW5hbWVzcGFjZS5wb2Qu
Y2x1c3Rlci5sb2NhbDBZMBMGByqGSM49AgEGCCqGSM49AwEHA0IABHk8n58E4xrn
xz5OEpCKDLTHvbimMiFtjsK/cOqZIMKgByajeHp0f9VkdBO3Oao/Qm9LhpXqNjTj
eXV7ZJ8KNrSgdjB0BgkqhkiG9w0BCQ4xZzBlMGMGA1UdEQRcMFqCJW15LXN2Yy5t
eS1uYW1lc3BhY2Uuc3ZjLmNsdXN0ZXIubG9jYWyCJW15LXBvZC5teS1uYW1lc3Bh
Y2UucG9kLmNsdXN0ZXIubG9jYWyHBKyoABiHBAoAIgIwCgYIKoZIzj0EAwIDSAAw
RQIgMZ86FYzPq49T6ha1EitkeaMmBs1t6ng+W9FNXMoY4TQCIQCeM56ZiVbvQXkT
29d0ZYnkNsgOiGvwd4ov4FOcfCWfOw==
-----END CERTIFICATE REQUEST-----
Secure images Images come from the container registry (docker hub by default)
AWS, Azure, etc, Custom also possible
By logging with private Docker hub account after login, config is updated
# "~/.docker/config.json" [noeol] 10L, 174C 1,1 All
{
"auths": {
"<https://index.docker.io/v1/>": {
"auth": "Y2R2ZWw6WjIxxxxxZXSlczRFE2QlQ="
}
},
"HttpHeaders": {
"User-Agent": "Docker-Client/19.03.13 (linux)"
}
docker images && docker pull image busybox
tag and push (after logging in to containter registry)
docker tag busybox:1.28.4 [privatecr.io/busybox:latest](<http://privatecr.io/busybox:latest>) & docker push privatecr.io/busybox:latest
specify a secret container registry named acr (avoid using unverified registries)
kubectl create secret docker-registry acr --docker-server=https://privatecr.io --docker-username=usr --docker-password='xxx' --docker-email=usr@mail.com
set service account to use new acr
kubectl patch serviceaccount default -p '{"imagePullSecrets": [{"name": "acr"}]}'
serviceaccount/default patched
kubectl get sa default -o -yaml
apiVersion: v1
imagePullSecrets: #<----- new
- name: acr #<----- new
kind: ServiceAccount
metadata:
creationTimestamp: "2020-09-29T06:59:00Z"
name: default
namespace: default
resourceVersion: "379"
selfLink: /api/v1/namespaces/default/serviceaccounts/default
uid: 8ccd9095-db8b-4f3a-892f-6e5c65caf419
secrets:
- name: default-token-6sw8s
in new pods:
...
spec:
containers:
- name: busybox
image: privatecr.io/busybox:latest #<---- good practice to keep the cr but optional
imagePullPolicy: Always #<--- always get the image, even if on disk
...
Security contexts Access control for a pod or containers, access to a file or process.
Applicable to all containers in a pod, as described in its yaml
kubectl run pod-default --image alpine --restart Never -- /bin/sleep 999999
# running as user root
kubectl exec pod-default -- id
uid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon),3(sys),4(adm),6(disk),10(wheel),11(floppy),20(dialout),26(tape),27(video)
running a pod as a different user
apiVersion: v1
kind: Pod
metadata:
name: alpine-user-context
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
runAsUser: 405
# runAsNonRoot: true #<---- may no work if intented as root
# privileged: true #<---- grant access to pod level (devices)kubectl exec alpine-user-context -- id
uid=405(guest) gid=100(users)
Running container in priviledged mode with securityContext privileged: true
kubectl exec -it privileged-pod -- ls /dev | wc -l
38 #<--- only 4 if not privileged
...
securityContext:
capabilities:
add:
- ["NET_ADMIN", "SYS_TIME"]
Add specific capabilities (modify kernel):
kubectl exec -it kernel-pod -- date +%T -s "10:00:00"
Removing specific capabilities (e.g., ownership)
...
securityContext:
capabilities:
drop:
- CHOWN
Writing only to volumes (read only file system)
apiVersion: v1
kind: Pod
metadata:
name: readonly-pod
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
readOnlyRootFileSystem: true
volumeMounts:
- name: my-volume
mountPath: /volume
readOnly: false
volumes:
- name: my-volume
emptyDir:
kubectl exec -it readonly-pod -- touch /file.md
touch: /file.md: Read-only file system
command terminated with exit code
kubectl exec -it readonly-pod -- touch /volume/file.md
kubectl exec -it readonly-pod -- ls /volume
file.md
Security context at the pod level
apiVersion: v1
kind: Pod
metadata:
name: group-context
spec:
securityContext:
fsGroup: 555 #<--- default group is 555
supplementalGroups: [666, 777]
containers:
- name: first
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
runAsUser: 111 #<--- first container run as user 111
volumeMounts:
- name: shared-volume
mountPath: /volume
readOnly: false
- name: second
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
runAsUser: 2222 #<--- second container run as user 2222
volumeMounts:
- name: shared-volume
mountPath: /volume
readOnly: false
volumes:
- name: shared-volume
emptyDir:
default user and group as specified IN the volume, otherwise group is root
kubectl exec -it group-context -c first -- sh
/ $ id
uid=111 gid=0(root) groups=555,666,777
/ $ touch /volume/file && ls -l /volume
total 0
-rw-r--r-- 1 111 555 0 Oct 20 07:33 file
touch /tmp/file && ls -l /tmp
total 0
-rw-r--r-- 1 111 root 0 Oct 20 07:35 file
Securing persistent key value stores Passed info into containers might be sensitive and need to be persistent
Use secrets: maps with key values
Not best practice to expose secrets in environment variables
Kept on in memory, not written to physical storage (tmpfs: in memory storage)
Secrets are decoded before use
kubectl get secrets
use kubectl describe to check secrets in a pod
Volumes:
default-token-6sw8s:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-6sw8s
...
Mounts:
/var/run/secretes/kubernetes.io/serviceaccount from default-823js
kubectl describe secret default-token-6sw8s
Name: default-token-6sw8s
Namespace: default
Labels: <none>
Annotations: kubernetes.io/service-account.name: default
kubernetes.io/service-account.uid: 8ccd9095-db8b-4f3a-892f-6e5c65caf419
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1025 bytes
namespace: 7 bytes
token: eyJhbGciOiJ...
Create a Secret certificate and a key
openssl genrsa -out https.key 2048
openssl req -new -x509 -key https.key -out https.cert -days 3650 -subj /CN=www.example.com
touch file
kubectl create secret generic example-https --from-file=https.key --from-file=https.cert --from-file=file
kubectl get secrets example-https -o yaml
apiVersion: v1
data:
file: ""
https.cert: LS0tLS1CRUdJTiBDRVJU== #<--- base64 encoded
https.key: LS0tLS1CRUdJTiBDRVJU== #<--- base64 encoded
kind: Secret
metadata:
creationTimestamp: "2020-10-20T07:51:34Z"
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:data:
.: {}
f:file: {}
f:https.cert: {}
f:https.key: {}
f:type: {}
manager: kubectl
operation: Update
time: "2020-10-20T07:51:34Z"
name: example-https
namespace: default
resourceVersion: "382860"
selfLink: /api/v1/namespaces/default/secrets/example-https
uid: 6a395fdd-ef7e-47ea-87cd-34c5e7101a59
type: Opaque
Mount secret on the pod
- image: nginx:alpine
name: web-server
volumeMounts:
- name: certs
mountPath: /etc/nginx/certs #<-- where is mounted
readOnly: true
volumes:
...
- name: certs
secret:
secretName: example-https
kubectl exec example-https -c web-server -- mount | grep cert tmpfs on /etc/nginx/certs type tmpfs (ro, relatime)
tmpfs: not written on disk
Hands on Create a clusterRole to access a PersistentVolume
Check persistent volumes kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
database-pv 1Gi RWO Retain Available local-storage 55m
Create ClusterRole and ClusterRoleBinding kubectl create clusterrole pv-reader --resource=pv --verb=get,list
clusterrole.rbac.authorization.k8s.io/pv-reader created
kubectl create clusterrolebinding pv-test --clusterrole=pv-reader --serviceaccount=web:default
clusterrolebinding.rbac.authorization.k8s.io/pv-test created
create and access pod to curl resource kubectl -f create pod.yaml apiVersion: v1
kind: Pod
metadata:
name: curlpod
namespace: web
spec:
containers:
- name: main
image: tutum/curl
command: ["sleep", "3600"]
- name: proxy
image: linuxacademycontent/kubectl-proxy
restartPolicy: Always
kubectl exec -it curlpod -n web -- sh
# defaults to main container
~ curl http:localhost:8001/api/v1/persistentvolumes
{
"kind": "PersistentVolumeList",
"apiVersion": "v1",
...
Monitoring Components Check application resource usage at pod, node cluster levels
Increase performance and reduce bottlenecks
Metrics server: Accessed via API, query each kubelet for CPU, Mem usage
Check metrics configuration
kubectl get --raw /apis/metrics.k8s.io
kubectl top collect info about nodes, current usage of all pods (describe only shows limits)
node pod --all-namespaces -n NAMESPACE -l key=value name-of-pod name-of-pod --containers kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ed092a70c01c.mylabserver.com 154m 7% 1190Mi 31%
f2c3d18a641c.mylabserver.com 196m 9% 1602Mi 42%
fc9ccdd4e21c.mylabserver.com 132m 6% 1194Mi 31%
kubectl top pod
NAME CPU(cores) MEMORY(bytes)
alpine-user-context 0m 0Mi
configmap-pod 0m 0Mi
dns-example 0m 7Mi
group-context 0m 1Mi
kubectl top pod --all-namespaces
...
kubectl top pod -n kube-system
...
kubectl top pod -l env=dev
...
kubectl top pod nginx
NAME CPU(cores) MEMORY(bytes)
nginx 0m 2Mi
kubectl top pods pod-example --containers
POD NAME CPU(cores) MEMORY(bytes)
pod-example second 0m 0Mi
pod-example first 0m 0Mi
Application in a cluster Detect resource utilization automatically
Liveness probe: Check if container is alive (if fails, restarts container) httpGet, tcpSocket, exec (run arbiratry code)
Readiness probe: Ready to receive client requests (if fails, no restart, remove from endpoints) apiVersion: v1
kind: Pod
metadata:
name: liveness
spec:
containers:
- image: linuxacademycontent/kubeserve
name: kubeserve
livenessProbe:
httpGet:
path: /
port: 80
---
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
periodSeconds: 5
if readiness probe fails, no pod created and removed from endpoints kubectl get ep
Cluster component logs TODO: Cluster logs diagram Check /var/log/containers may consume all disk space, use sidecar pattern with a logger.
kubelet (process) logs at /var/log
Use the sidecar pattern to mount for each container and query logs separately
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- image: busybox
name: count
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Use kubectl logs
kubectl logs counter count-log-1 && kubectl logs counter count-log-2
Log rotation may be needed, but not supported in k8s
Application Logs Containers write logs to stdout, but runtime (Docker) redirect to files. K8s can pick up these and make them accessible via:
kubectl logs
pod-namepod-name -c container-namepod-name --all-containers=true-l run=nginxLogs from a terminated pod: kubectl logs -p - c container pod
streaming flag -f tail --tail=20 last hour --since=1h from deployment kubectl logs deployment/nginx from container in deployment kubectl logs deployment/nginx -c nginx > file.txt Hands on Find failing Pod kubectl get pods --all-namespaces Find logs and save to file for that pod kubectl logs pod4 -n web > error4.log Failure identification & troubleshooting Ideas for troubleshooting:
check pods for event and condiftions check coredns pod listing events for pod decribe pod for image pull error Application Application developer should put all info needed in log files
AppComErr, CrashKoopBackoff, FailedMountErr, Pending, RbacErr, ImagePullErr, DiscoveryErr
k8s allows a termination message to be written to a file
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- image: busybox
name: main
command:
- sh
- -c
- 'echo "It''s enough" > /var/termination-reason; exit 1'
terminationMessagePath: /var/termination-reason #<--- file to write to
kubectl describe pod my-pod
...
Last State: Terminated
Reason: Error
Message: It's enough
Built-in liveness probe in kubernetes
livenessProbe:
httpGet:
path: /healthz #<--- not all images have a healthz endpoint
port: 8081
Troubleshooting checklist
Find pods with Error status kubectl describe and check events, check state.reasonOn running pods modify some attributes with kubectl editotherwise recreate (5) kubectl logs my-podkubectl get po my-pod -o yaml and scan for reasons or inconsistenciesIf not a deployment, recreate the pod kubeclt get po my-pod -o yaml --export > file.yaml Control plane control plane
+------------------------------------------+
| |
| +------------+ +------+ |
| | | | | |
| | API server +---------->+ etcd | |
| | | | | |
| +-----+-+----+ +------+ |
| ^ ^ |
| | +-------------------+ |
| | | |
| +-----+-------+ +-------+-----+ |
| |scheduler | | controller | |
| | | | manager | |
| +-------------+ +-------------+ |
| |
+------------------------------------------+
Considerations
choose infra vendor with SLA guarantees take snapshot from storage use deployments and services to load balance use federation to join cluster together review events & schedulers kubectl get events -n kube-systemkubectl logs -n kube-system [kube-scheduler-f2c3d18a641c.mylabserver.com](<http://kube-scheduler-f2c3d18a641c.mylabserver.com/>)services starte when the server starts automatically systemctl start docker && systemctl enable kubeletdisable swap to run kubelet swapoff -a && vim /etc/fstab > comment swap line firewall issues, disable it systemctl disable firewalld Public IPs in kube config files? issues afterward, tie to static IP view used default from kubeadm: see kubectl config view Make API server HA (replicate) Worker node checklist
Check for faulty nodes kubectl get no Review kubectl describe no node_name Find details like IP address with kubectl get nodes -o wide Recreate a node if irresponsive and troubleshooting fails View journalctl -u kubelet logs May check /var/log/syslog for more details on kubelet status Networking Intercluster communication and services
kubectl run hostnames --image=[k8s.gcr.io/serve_hostname](<http://k8s.gcr.io/serve_hostname>) --replicas=3
kubectl expose pod hostnames --port=80 --target-port=9376
kubectl run -it --rm --restart=Never busybox3 --image=busybox:1.28 -- sh
### checking for dns resolution, hostnames and default
/ # nslookup hostnames
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: hostnames
Address 1: 10.104.243.218 hostnames.default.svc.cluster.local
/ #
/ # nslookup kubernetes.default
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
/ #
Verify target port, container port, protocol kubectl get svc hostnames -o json ...
"spec": {
"clusterIP": "10.104.243.218",
"ports": [
{
"port": 80,
"protocol": "TCP",
"targetPort": 9376
check endpoints with kubectl get ep && use wget to check access via target port NAME ENDPOINTS AGE
hostnames 10.244.79.31:9376 10m
kubernetes 172.31.31.60:6443 22d
kubeserve 10.244.194.194:80,10.244.194.196:80,10.244.79.7:80 9d
nginx 10.244.194.241:80,10.244.79.8:80 6d16h
check kube-proxy runs on the nodes ps auxw | grep kube-proxy check iptables are up to date in kube-proxy kubectl exec -it kube-proxy-29v2s -n kube-system -- sh
> iptables-save | grep hostnames
> -A KUBE-SEP-54E5H2EQMA5FL7LP -s 10.244.79.31/32 -m comment --comment "default/hostnames:" -j KUBE-MARK-MASQ
...
You may replace network plugin, e.g., from flannel to calico via kubectl delete and apply, check docs. Hands-on 1. Identifying broken pods: kubectl get po --all-namespaces
web nginx-856876659f-2fskf 0/1 ErrImagePull 0 3m14s
web nginx-856876659f-5k8lr 0/1 ImagePullBackOff 0 3m15s
web nginx-856876659f-nfxt7 0/1 ErrImagePull 0 3m14s
web nginx-856876659f-v7mjr 0/1 ImagePullBackOff 0 3m14s
web nginx-856876659f-vtmxd 0/1 ImagePullBackOff 0 3m14s
2. Find failure reason: kubectl describe po nginx-xxxx -n web
error
Failed to pull image "nginx:191
solved by:
# check events
kubectl describe po nginx-xxxx -n web
# edit running pod spec image
kubectl edit po nginx-xxxx -n web
#OR (better)
kubectl edit deploy nginx -n web
#switch yaml to image=nginx
:wq
3. Verify replica set kubectl get rs -w web
4. Access pod directly using interactive busybox pod
kubectl run busybox --image=busybox --rm -it --restartNever=true -- sh
wget -qO- 10.244.1.2:80 #<--- get ip using kubectl get -o wide